《高性能Mysql》读书笔记01
1 说明
1.1 主要内容
本系列的记录主要是对阅读《高性能mysql》第三版过程中,部分内容的摘录和一些网上相关的总结分享,后续自己会找些实例进行说明,加深理解。
本篇主要记录:
- 通过一些mysql图在头脑中构建出一幅Mysql各组件之间如何协同工作的架构图
- 我们经常关心的表的设计与数据类型优化
1.2 系列链接
这是第一篇,等多写几篇后补充
2 Mysql逻辑架构
2.1 架构逻辑视图
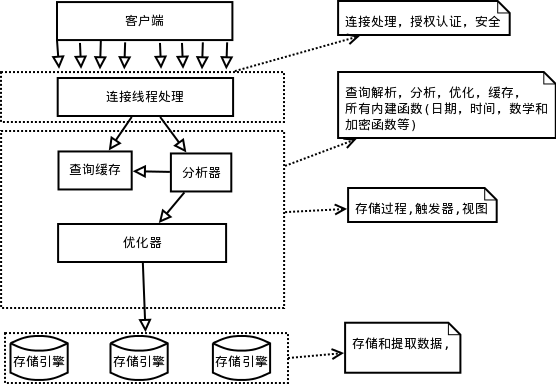
每个虚线框为一层,总共三层。
- 第一层,服务层(为客户端服务):为请求做连接处理,授权认证,安全等。
- 第二层,核心层:查询解析,分析,优化,缓存,提供内建函数;存储过程,触发器,视图。
- 第三层,存储引擎层,不光做存储和提取数据,而且针对特殊数据引擎还要做事务处理。
2.2 连接管理与安全性(第一层 服务层)
2.2.1 处理流程
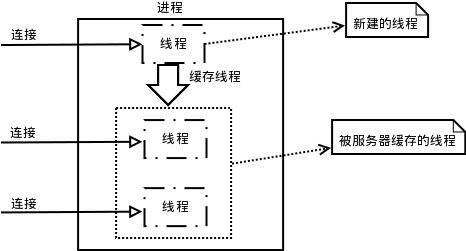
- 每个连接的查询都在一个进程中的线程完成。
- 服务器负责缓存线程,所以服务层不需要为每个连接新建线程。
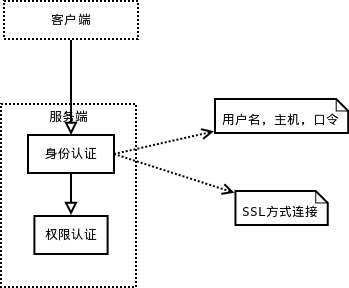
2.2.2 认证流程
2.3 优化与执行
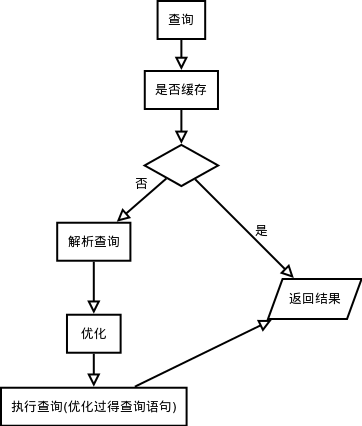
- 在解析查询之前,服务器会“询问”是否进行了查询缓存(只能缓存SELECT语句和相应结果)。缓存过的直接返回结果,未缓存的就需要进行解析查询,优化,重新执行返回结果。
- 解析查询时会创建一个内部数据结构(树),然后对其进行各种优化。
- 优化:重写查询,决定查询的读表顺序,选择需使用的索引。
3 表的设计与数据类型优化
选择数据类型只要遵循小而简单的原则就好,越小的数据类型通常会更快,占用更少的磁盘、内存,处理时需要的CPU周期也更少。越简单的数据类型在计算时需要更少的CPU周期,比如,整型就比字符操作代价低,因而会使用整型来存储ip地址,使用DATETIME来存储时间,而不是使用字符串。
这里总结几个可能容易理解错误的技巧:
- 通常来说把可为NULL的列改为NOT NULL不会对性能提升有多少帮助,只是如果计划在列上创建索引,就应该将该列设置为NOT NULL。
- 对整数类型指定宽度,比如INT(11),没有任何卵用。INT使用4字节存储空间,那么它所表示的数值范围已经确定,所以INT(1)和INT(20)对于存储和计算是相同的。
- UNSIGNED表示不允许负值,大致可以使正数的上限提高一倍。比如TINYINT存储范围是-128 ~ 127,而UNSIGNED TINYINT存储的范围却是0 – 255。
- 通常来讲,没有太大的必要使用DECIMAL数据类型。即使是在需要存储财务数据时,仍然可以使用BIGINT。比如需要精确到万分之一,那么可以将数据乘以一百万然后使用BIGINT存储。这样可以避免浮点数计算不准确和DECIMAL精确计算代价高的问题。
- TIMESTAMP使用4个字节存储空间,DATETIME使用8个字节存储空间。因而,TIMESTAMP只能表示1970 –2038年,比DATETIME表示的范围小得多,而且TIMESTAMP的值因时区不同而不同。
- 大多数情况下没有使用枚举类型的必要,其中一个缺点是枚举的字符串列表是固定的,添加和删除字符串(枚举选项)必须使用ALTER TABLE(如果只只是在列表末尾追加元素,不需要重建表)。
- 表的列不要太多。原因是存储引擎的API工作时需要在服务器层和存储引擎层之间通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码成各个列,这个转换过程的代价是非常高的。如果列太多而实际使用的列又很少的话,有可能会导致CPU占用过高。
- 大表ALTER TABLE非常耗时,MySQL执行大部分修改表结果操作的方法是用新的结构创建一个张空表,从旧表中查出所有的数据插入新表,然后再删除旧表。尤其当内存不足而表又很大,而且还有很大索引的情况下,耗时更久