关于使用Flume(NG)打造日志系统的分享与思考
Table of Contents
1 主要内容
- Flume(NG)介绍
- Flume(NG)知识分享
- 怎么在校宝项目中使用Flume(NG)的思考
- 其他应用场景
- 监控
- 未来与Kafka进行结合
2 Flume(NG)介绍
Flume(NG)是一个分布式,可靠,可用的系统,它能够将不同数据源的海量日志数据进行高效收集,聚合,移动,最后存储到一个中心化数据存储系统中。
一方面,Flume(NG)支持在日志系统中定制各种数据发送方,用于收集数据;另一方面,Flume提供对数据进行简单的处理,并写到各种数据接收方(比如文本,HDFS,Hbase等)的能力。
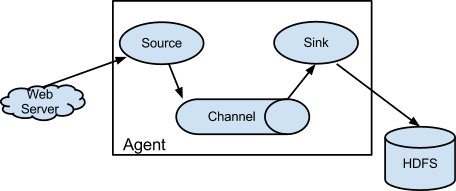
flume数据流由事件(event)贯穿始终。事件是flume的基本数据单位,它携带日志数据(字节数组形式)并且携带头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会对数据做特定的格式化,然后Source会把事件推入(单个或者多个)Channel中。可以把Channel看成是一个缓存区,它将保存事件直到Sink处理完该事件,Sink负责持久化日志或者把事件推向另一个Source。
3 Flume(NG)知识分享
3.1 核心概念
下表是Flume的一些主要核心概念
| 名称 | 说明 |
|---|---|
| Event | 一个数据单元,带有一个可选的消息头 |
| Flow | Event从源点到达目的点的迁移的抽象 |
| Client | 操作位于源点处的Event,将其发送到Flume Agent |
| Agent | 一个独立的Flume进程,包含组件Source,Channel,Sink |
| Source | 用来消费传递到该组件的Event |
| Channel | 中转Event的一个临时存储,保存有Source组件传递过来的Event |
| Sink | 从Channel中读取并移除Event,将Event传递到Flow Pipeline中的下一个Agent(如果有的话) |
一个基本的Flow配置:
# list the sources, sinks and channels for the agent <Agent>.sources = <Source1> <Source2> <Agent>.sinks = <Sink1> <Sink2> <Agent>.channels = <Channel1> <Channel2> # set channel for source <Agent>.sources.<Source1>.channels = <Channel1> <Channel2> ... <Agent>.sources.<Source2>.channels = <Channel1> <Channel2> ... # set channel for sink <Agent>.sinks.<Sink1>.channel = <Channel1> <Agent>.sinks.<Sink2>.channel = <Channel2>
尖括号里面的内容是可以根据实际业务和需求进行修改的。
上面的配置内容中,第一组中配置Source,Sink,Channel,他们的值可以有一个或者多个;第二组中配置Source将数据存储(Put)到那个Channel中,可以存储到一个或多个Channel中;第三组配置Sink从哪一个Channel中(Task)数据,一个Sink只能从一个Channel中取数据。
3.2 常见的Flow Pipeline
数据来源Flume官网。
3.2.1 多个Agent顺序连接

可以将多个Agent顺序连接起来,将最初的数据源进过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接下Agent的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响到整个Flow上的Agent的收集服务。
3.2.2 多个Agent的数据汇聚到同一个Agent
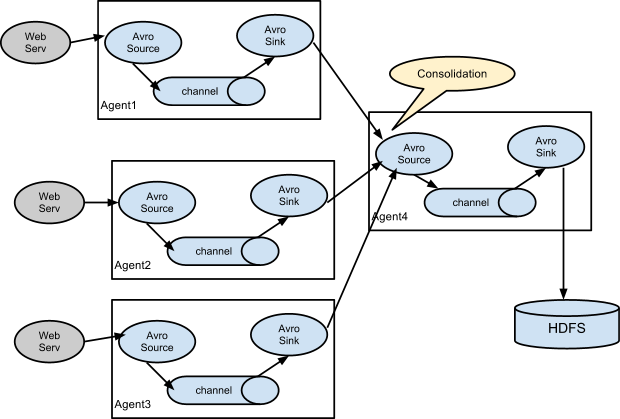
这种情况应用的场景比较多,比如要收集web网站的用户行为日志,Web网站为了应用的可用性使用负载均衡的集群模式,每个节点都会产生用户行为日志,可以为每个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据汇总到一个用来存储数据的存储系统,如:HDFS。
3.2.3 多路(Multiplexing)Agent
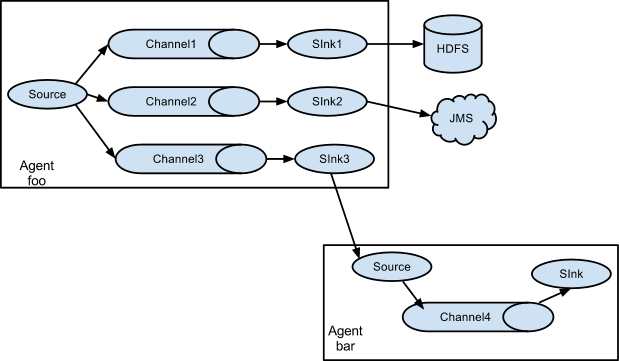
这种模式,有两种方式,一种用来复制(replication),另一种用来分流(Multiplexing)。
- Replication方式,可以将最前端的数据源复制多份,分别传递到多个channel中,每个channel接收到的数据都是相同的,配置格式,如下所示:
# List the sources, sinks and channels for the agent <Agent>.sources = <Source1> <Agent>.sinks = <Sink1> <Sink2> <Agent>.channels = <Channel1> <Channel2> # set list of channels for source (separated by space) <Agent>.sources.<Source1>.channels = <Channel1> <Channel2> # set channel for sinks <Agent>.sinks.<Sink1>.channel = <Channel1> <Agent>.sinks.<Sink2>.channel = <Channel2> <Agent>.sources.<Source1>.selector.type = replicating
上面指定了selector的type的值为replication,其他的配置没有指定,使用的Replication方式,Source1会将数据分别存储到Channel1和Channel2,这两个channel里面存储的数据是相同的,然后数据被传递到Sink1和Sink2。
- Multiplexing方式,selector可以根据header的值来确定数据传递到哪一个channel,配置格式,如下所示:
# Mapping for multiplexing selector <Agent>.sources.<Source1>.selector.type = multiplexing <Agent>.sources.<Source1>.selector.header = <someHeader> <Agent>.sources.<Source1>.selector.mapping.<Value1> = <Channel1> <Agent>.sources.<Source1>.selector.mapping.<Value2> = <Channel1> <Channel2> <Agent>.sources.<Source1>.selector.mapping.<Value3> = <Channel2> #... <Agent>.sources.<Source1>.selector.default = <Channel2>
上面selector的type的值为multiplexing,同时配置selector的header信息,还配置了多个selector的mapping的值,即header的值:如果header的值为Value1、Value2,数据从Source1路由到Channel1;如果header的值为Value2、Value3,数据从Source1路由到Channel2。
3.3 基本功能
Flume都支持哪些功能,了解它的功能集合,能够让我们在应用中更好的选择哪一种解决方案。Flume实际的功能会围绕着Agent的三个组件Source,Channel,Sink来看支持哪些技术或者协议。
3.3.1 Flume Source
| Source类型 | 说明 |
|---|---|
| Avro Source | 支持Avro协议(实际上是Avro RPC),内置支持 |
| Thrift Source | 支持Thrift协议,内置支持 |
| Exec Source | 基于Unix的command在标准输出上生产数据 |
| JMS Source | 从JMS(消息,主题)中读取数据 |
| Spooling Directory Source | 监控指定目录内数据的变更 |
| Twitter 1% firehose Source | 通过API持续下载Twitter数据,试验性质 |
| Netcat Source | 监控某个端口,将流经端口的每个文本行数据作为Event输入 |
| Sequence Generator Source | 序列生成器数据源,生产序列数据 |
| Syslog Source | 读取syslog数据,产生Event,支持UDP和TCP两种协议 |
| HTTP Source | 基于HTTP POST或GET方式的数据源,支持JSON,BLOB表示格式 |
| Legacy Source | 兼容老的Flume OG中Source(0.9.x版本) |
3.3.2 Flume Sink
| Sink类型 | 说明 |
|---|---|
| HDFS Sink | 数据写入HDFS |
| logger Sink | 数据写入日志文件 |
| Avro Sink | 数据被转换成Avro Event,然后发送到配置的RPC端口上 |
| Thrift Sink | 数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| IRC Sink | 数据在IRC上进行回收 |
| File Roll Sink | 存储数据到本地文件系统 |
| Null Sink | 丢弃所有数据 |
| HBase Sink | 数据写入Hbase数据库 |
| Morphline Solr Sink | 数据发送到Solr搜素服务器(集群) |
| ElasticSearch Sink | 数据发送到Elastic Search搜素服务器 |
| Kite Dataset Sink | 写数据到Kite Dataset中 |
| Custom Sink | 自定义Sink实现 |
3.3.3 Flume Channel
| Channel类型 | 说明 |
|---|---|
| Memory Channel | Event数据存储在内存中 |
| JDBC Channel | Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
| File Channel | Event数据存储在磁盘文件中 |
| Spillable Memory Channel | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件 |
| Pseudo Transaction Channel | 测试用途 |
| Custom Channel | 自定义Channel实现 |
3.4 应用实践
在windows上部署尝试:
3.4.1 安装
- 安装java,配置环境变量。
- 安装flume,下载地址,下载后直接解压即可。
3.4.2 运行
- 创建配置文件:在解压后的文件apache-flume-1.7.0-bin/conf下创建一个example.conf,内容如下。
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
- 打开cmd进入到apache-flume-1.7.0-bin\bin目录下,运行如下命令。
flume-ng.cmd agent -conf ../conf -conf-file ../conf/example.conf -name a1 -property flume.root.logger=INFO,console
- 另外打开一个cmd窗口,运行如下命令。
telnet localhost 44444
4 怎么在校宝项目中使用Flume(NG)的思考
建立日志系统的目的:
负责收集,处理,存储,查询应用中操作的各种日志,目前定位异常问题已经有了opserver,暂时不用做重复的工作,那么打造这个日志系统更多的是面向记录系统中各个功能操作日志,如课程修改,订单变更等等,这些日志可以用于如客户实施,客服,管理层等其它方面做指导,分析和问题定位。
利用Flume强大的对多数据源的收集功能,打造统一的日志平台。
4.1 项目现状
当前项目中的日志数据
- 通过log4net落地到文件中
- 利用StackExchange.Exceptional,记录日志到统一异常日志库
4.2 如何落地
下面是我觉得可以实施的一个思路:
第一阶段:对日志数据进行收集
- 不改变任何项目代码,引入Flume做配置进行log4net落地的日志进行收集
- 对各个项目或业务场景提供日志客户端方便接入日志收集
第二阶段:对收集的日志提交简单场景的查询
- 开发日志数据可视化的应用
- 做日志系统做监控服务,增加接入日志平台的项目或应用
第三阶段:对日志数据进行处理后存储
- 积累一些使用经验后,就不能盲目的收集日志,应该引入日志数据流处理,收集特定的日志数据
- 做分析处理,做预警等等
这一整套体系涉及知识不少,我也只是零散的了解了部分,还在不断学习中
5 其他应用场景
来自博客园欢醉的文章:几十条业务线日志系统如何收集处理?
比如我们在做一个电子商务网站,然后我们想从消费用户中访问点特定的节点区域来分析消费者的行为或者购买意图. 这样我们就可以更加快速的将他想要的推送到界面上,实现这一点,我们需要将获取到的她访问的页面以及点击的产品数据等日志数据信息收集并移交给Hadoop平台上去分析.而Flume正是帮我们做到这一点。现在流行的内容推送,比如广告定点投放以及新闻私人定制也是基于次,不过不一定是使用FLume。
5.1 flume+kafka+storm+mysql
用于构建大数据实时系统

5.2 Flume+HDFS+KafKa+Strom
美团的应用于实现实时推荐,反爬虫服务等服务
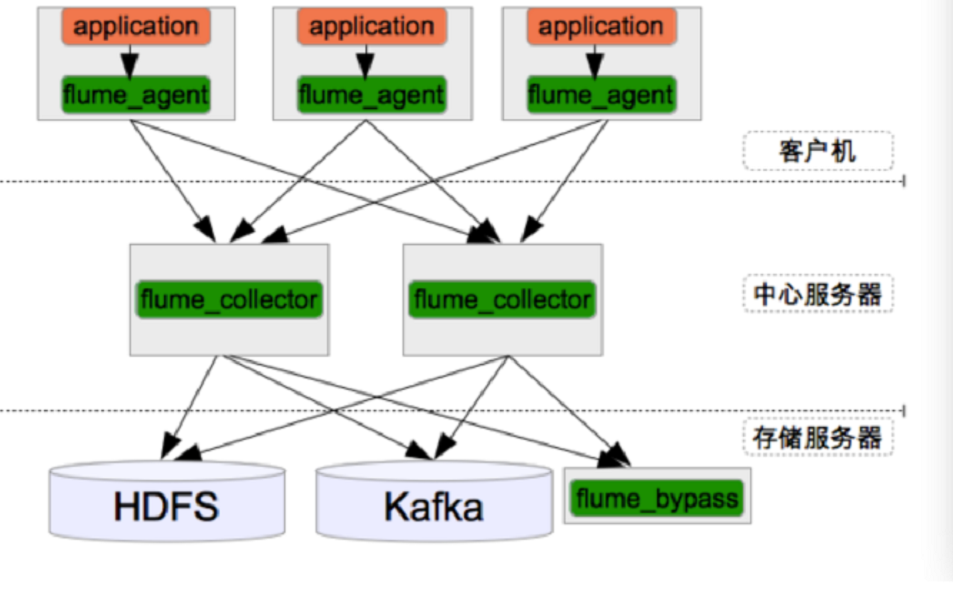
5.3 Flume+Hadoop+Hive
用于实现离线分析网站用户浏览行为路径
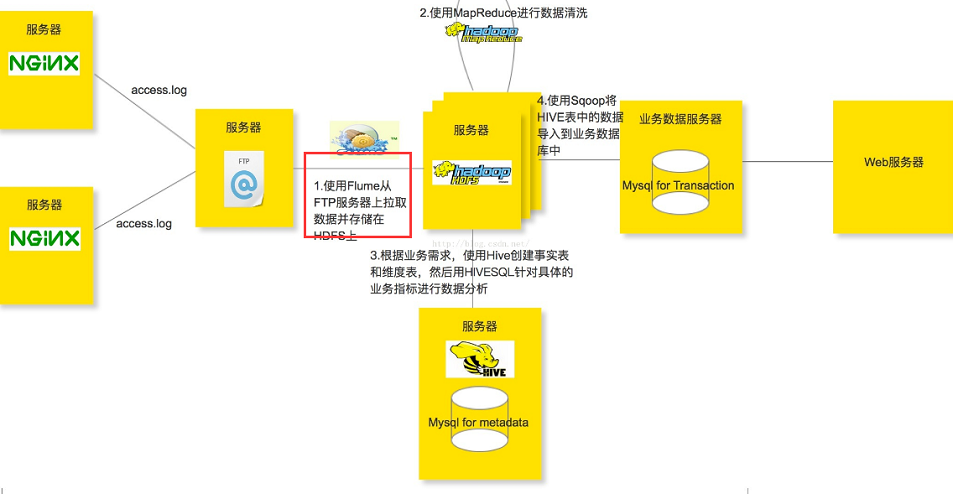
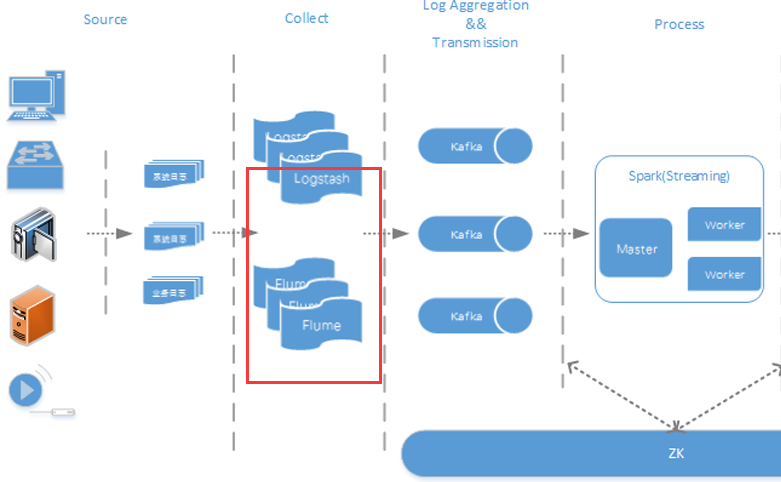
5.4 Flume+Logstash+Kafka+Spark Streaming、
用于进行实时日志处理分析
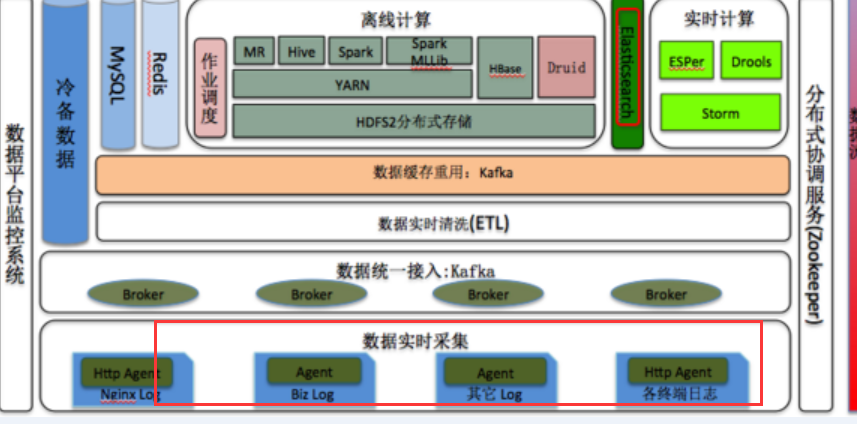
5.5 Flume+Spark + ELK
新浪应用于数据系统实时监控平台
6 监控
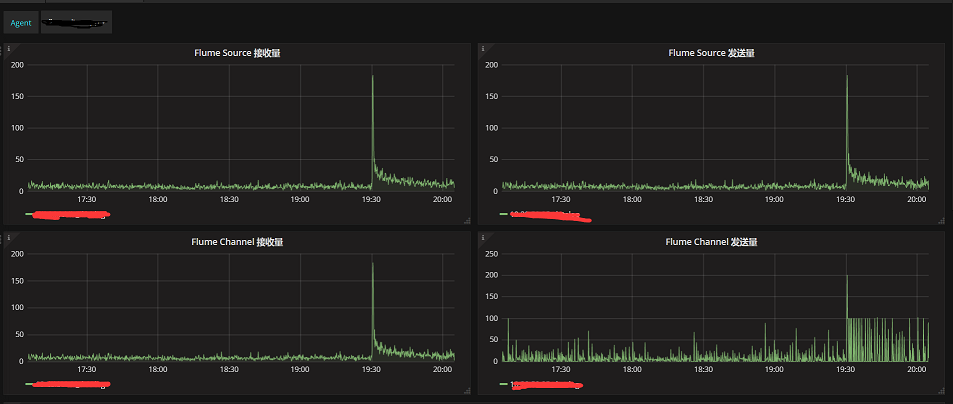
加上监控,可以在出现问题时快速定位问题,解决问题。flume官方提供了JMX Reporting,Ganglia Reporting,JSON Reporting,自定义报告四种方式。
一般会先用JSON的方式,可以和Telegraf结合使用,下面是网上实现Flume+Telegraf的监控截图:
7 未来与Kafka进行结合
Kafka是由Apache软件基金会开发的一个开源消息中间件项目。可以理解为一个cache系统。甚至可以把它理解为一个广义的数据库,里面可以存放一定时间的数据。

建设日志系统初期只是用于向Hadoop或HBase导入数据用Flume就可以,如果后面数据需要被多个应用程序处理,可以和Kafka结合使用。
比较典型的用法是: 线上数据 -> flume -> kafka -> hdfs -> MR离线计算 或者: 线上数据 -> flume -> kafka -> storm。
对于搭建日志系统而言整体上可以参考下面几个方面:
- 日志采集(Logstash/Flume, SDK wrpper)
- 实时消费(Storm,Flink,Spark Streaming)+离线存储(HDFS,Object Storage,Nosql)
- 离线分析(Presto,Hive,Hadoop)
- 如果需要搜索可以加上搜索引擎(ES,ELK)
8 感谢
技术其实也是一件很严肃的事情,我也会怕犯错,也就想着真正把很多东西学的很好之后再出来分享,但交流分享的过程何尝不是一次学习。
很感谢师傅鼎鼎给予的指导。
参考链接