数据结构与算法分析读书笔记系列03-表、栈和队列
Table of Contents
1 前言
每一个有意义的程序都将明晰地至少使用一种这样的数据结构,而栈则在程序中总是要间接地用到,不管你在程序中是否做了申明。
2 抽象数据类型
程序设计的基本法则之一是例程不应超过一页。这可以通过把程序分割为一些模块(module)来实现。每个模块是一个逻辑单位并执行某个指定的任务,它通过调用其他模块而使本身很小。
模块化有几个优点:
- 调试小程序比调试大程序要容易得多。
- 多个人同时对一个模块化程序编程要更容易。
- 一个写的好的模块化程序把某些依赖关系只局限在一个例程里,这样使得修改起来会更容易。
抽象数据类型(abstract data type,ADT)是一些操作的集合。抽象数据类型是数学的抽象;在ADT的定义中不涉及如何实现操作的集合。这可以看作是模块化设计的扩充。我们基本的想法是,这些操作的实现只在程序中编写一次,而程序中任何其他部分需要在该ADT上运行其中的一种操作时可以通过调用适当的函数来进行。
3 表ADT
我们将处理一般的形如A1 ,A2 ,A3 …,AN 的表。我们说,这个表的大小是N。我们称大小为0的表为空表(empty list)。
对于除空表外的任何表,我们说A(i+1) 后继Ai (或继Ai 之后)并称A(i-1) (i < N)前驱Ai (i > 1)。
3.1 表的简单数组实现
对表的所有操作都可以通过使用数组来实现。因为插入和删除的运行时间是如此的慢以及表的大小还必须事先已知,所以简单数组一般不用来实现表这种结构。
3.2 链表
为了避免插入和删除的线性开销,我们需要允许表可以不连续存储,否则表的部分或全部需要整体移动。
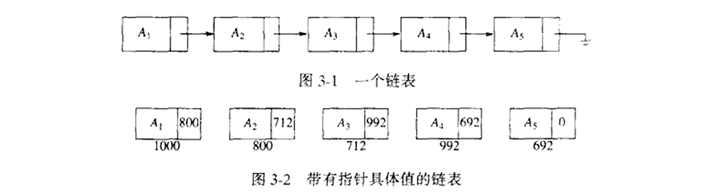
链表由一系列不必在内存中相连的结构组成。每一个结构均含有表元素和指向包含该元素后继元的结构的指针。我们称之为Next指针。最后一个单元的Next指针指向NULL。
3.3 程序设计细节
可能出问题的地方
- 并不存在从所给定义出发在表的前面插入元素的真正显性的方法。
- 从表的前面实行删除是一个特殊情况,因为它改变了表的起始端;编程中的疏忽将会造成表的丢失。
- 对于一般的删除,虽然指针的移动很简单,但是删除算法要求我们记住被删除元素前面的表元。
解决上面的问题:留出一个标志结点,有时候称之为表头(header)或哑结点(dummy node)。我们约定,表头的位置0处。

链表的编程实现






3.4 双链表
有时候以倒序扫描链表很方便。标准实现的方法此时无能无力,然而解决方法却很简单。只要在数据结构附加一个域,使它包含向前一个单元的指针即可。其开销是附加的链,它增加了空间的需求,同时也使得插入和删除的开销增加一倍,因为有更多的指针需要定位。另一方面,它简化了删除操作,因为你不再被迫使用一个指向前驱元的指针来访问一个关键字;这个信息是现成的。

3.5 循环链表
让最后的单元反过来直指第一个单元是一种流行的做法。它可以有表头,也可以没有表头(若有表头,则最后的单元就指向它),并且还可以是双向链表(第一个单元的前驱元指针指向最后的单元)。这无疑会影响某些测试,不过这种结构在某些应用程序中却很流行。

3.6 例子
3.6.1 多项式
3.6.2 基数排序(radix sort),有时也称为卡式排序(card sort)
如果我们有N个整数,范围从1到M(或从0到M-1),我们可以利用这性格信息得到一种快速的排序,叫做桶氏排序(bucket sort)。我们留置一个数据,称之为Count,大小为M,并初始化为零。于是。Count有M个单位(或桶),开始时他们都是空的。当Ai 被读入时Count[Ai]增1.在所有的输入被读入后,扫描数组Count,打印输出排好序的表。该算法花费O(M+N)。
基数排序时这种方法的推广。设我们有10个数,范围在0到999之间,我们将其排序。一般来说,这是0到Np - 1间的N个数,p是某个常数。显然我们不能使用桶排序,那样桶就太多了。我们的策略是使用多躺桶氏排序。自然的算法就是通过最高位(有效)“位”(对基数N所取的位)进行桶氏排序 ,然后对次最高(有效)位进行,等等。这种算法不能得出正确结果,但是如果我们用最低(有效)"位"优先的方式进行桶氏排序,那么算法将得到正确结果。
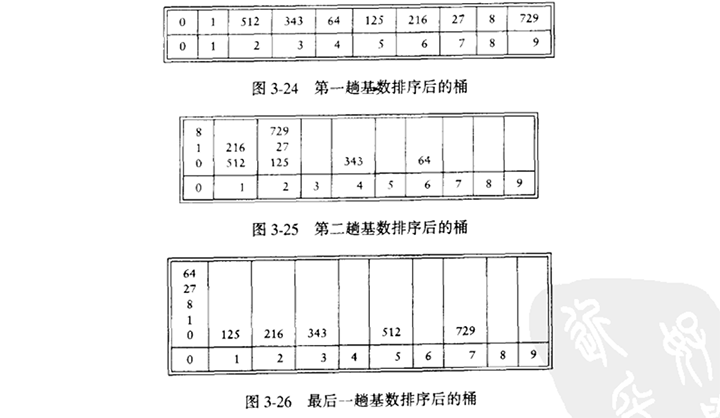
为使算法能够得出正确的结果,要注意唯一出错的可能是如果两个数出自同一个桶但顺序却是错误的。不过,前面各趟排序顺序保证了当几个数进入一个桶的时候,它们是以排序的顺序进入的。该排序的运行时间是O(P(N+B)),其中P是排序的躺数,N是要被排序的元素的个数,而B是桶数。本例,B = N。
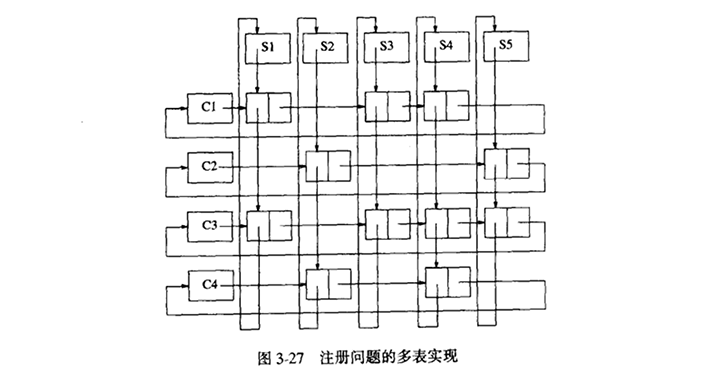
3.6.3 多重表
3.7 链表的游标实现
有些语言不支持指针,如果需要链表又不能使用指针,可以使用游标(cursor)实现法。
在链表的指针实现中有两个重要的特点:
- 数据存储在一组结构体中。每个结构体包含有数据以及指向下一个结构体的指针。
- 一个新的机构体可以通过调用malloc而从系统内存(global memory)得到,并可以通过调用free而被释放。
游标法必须能够模拟实现这两条特性。满足条件1的逻辑方法是要有一个全局的结构体数组。对于该数组中的任何单元,其数组下标可以用来代表一个地址。
模拟条件2,通过保留一个表(即freelist),这个表由不在任何表中的单元构成。
4 栈ADT
4.1 栈模型
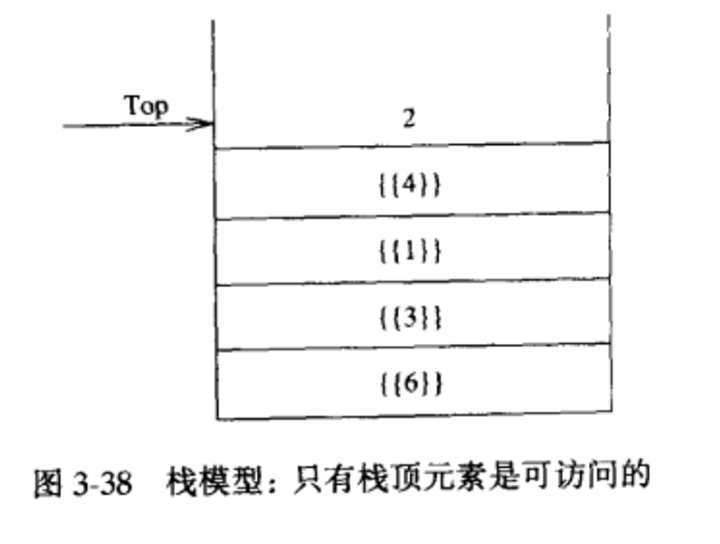
栈(stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫做栈的顶(top)。对栈的基本操作有Push(进栈)和Pop(出栈),前者相当于插入,后者则是删除最后插入的元素。
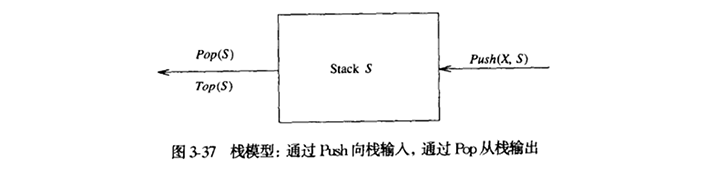
栈有时又叫做LIFO(后进先出表)。图3-37中描述的模型只象征着Push是输入操作而Pop和Top是输出操作。普通的清空栈的操作和判断空栈的测试都是栈的操作指令系统中的一部分,但对栈能做的,基本上也就是Push和Pop操作。
图3-38表示在进行若干操作后的一个抽象的栈。
4.2 栈的实现
由于栈是一个表,因此任何实现表的方法都能实现栈。两个流行的实现方法,一种方法使用指针,而另一种方法则使用数组。
4.2.1 栈的链表实现
栈的第一种实现方法是使用单链表。我们通过在表顶端插入来实现Push,通过删除表顶端元素来实现Pop。Top操作只是考查表顶端元素并返回它的值。有时Pop操作和Top操作合二为一。
栈的链表编程实现



很清楚,所有的操作均花费常数时间,因为这些例程没有任何地方涉及到栈的大小(空栈除外),更不用说依赖于栈大小的循环了。这种实现方法的缺点在于对malloc和free的调用的开销是昂贵的。有时候可以通过使用第二个栈避免。
4.2.2 栈的数组实现
另一种实现方法避免了指针并且可能是更流行的解决方案。这种策略的唯一潜在危害是我们需要提前声明一个数组的大小。一般来说,这并不是问题,因为在典型的应用程序中,即使有很多的栈操作,在任一时刻栈元素的实际个数不会太大。不过不能做到这一点,那么节省的做法是使用链表来实现。
用一个数组实现栈是很简单的。每一个栈有一个TopOfStack,对于空栈它是-1(这就是空栈的初始化)。为了将某个元素X压入到该栈中,我们将TopOfStack加1,然后置Stack[TopOfStack] = X,其中Stack是代表具体栈的数组。为了弹出栈元素,我们置返回值为Stack[TopOfStack]然后TopOfStack减1。
注意,这些操作不仅以常数时间运行,而且是以非常快的常数时间运行。在某些机器上。若在带有自增和自减寻址功能的寄存器上操作,则(整数的)Push和Pop都可以写成一条机器指令。
栈的数组编程实现



4.3 应用
4.3.1 平衡符号
编译器检查你的程序语法错误,但是常常由于缺少一个符号(如遗漏一个花括号或是注释起始符)引起编译器列出上百行的诊断,而真正的错误并没有找出。
这种情况下一个有用的工具就是检验是否每件事情都能成对出现的一个程序。
4.3.2 后缀表达式
1.1 3.2 + 9.9 + 6.99 * +
上面的这个记法叫做后缀(postfix)或逆波兰(reverse Polish)记法,计算这个问题最容易的方法是使用一个栈。
4.3.3 中缀到后缀的转换
栈不仅可以用来计算后缀表达式的值,而且还可以用栈将一个标准形式的表达式(或叫做中缀式(infix))转换成后缀式。
4.3.4 函数调用
该问题类似于平衡符号的原因在于,函数调用和函数返回基本类似于开括号和闭括号,二者想法是一样的。
5 队列ADT
像栈一样,队列(queue)也是表。然而,使用队列时插入在一端进行而删除则在另一端进行。
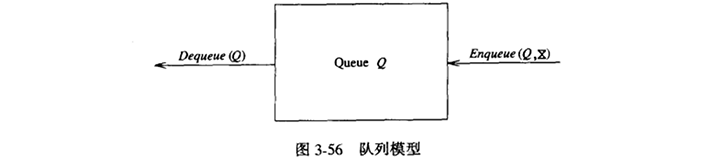
5.1 队列模型
队列的基本操作是Enqueue(入队),它是在表的末端(叫做队尾(rear))插入一个元素,还有Dequeue(出队),它是删除(或返回)在表的开头(叫做队头(front))的元素。
5.2 队列的数组实现
如同栈的情形一样,对于队列而言任何表的实现都是合法的。像栈一样,对于每一种操作,链表实现和数组实现都给出快速的O(1)运行时间。
对于每一个队列数据结构,我们保留一个数组Queue[]以及位置Front和Rear,它们代表队列的两端。我们还要记录实际存在于队列中的元素的个数Size。所有这些信息是作为一个结构的一部分,除队列例程本身外通常不会有例程直接访问它们。下图表示处于某个中间状态的一个队列。顺便指出,图中哪些空白单元是有着不确定的值的。特别地,前三个单元含有曾经属于该队列的元素。

操作是清楚的,为使一个元素X入队,我们让Size和Rear增1,然后值Queue[Rear] = X。若使一个元素出队,我们置返回值为Queue[Front],Size减1,然后使Front增1。
对于上述实现一个潜在问题是,队列满了,下一次入队就会是一个不存在的位置。简单的解决方法是,只要Front或Rear到达数组的尾端,它就又绕回开头。这种叫循环数组(circular array)实现。
实现回绕所需要的附加代码是极小的(它可能使得运行时间加倍)。如果Front或Rear增1使得超越了数组,那么其值就要重置为数组的第一个位置。
关于队列的循环实现,有两件事要警惕。
- 检测队列是否为空是很重要的,因为当队列为空时一次Dequeue操作将不知不觉地返回一个不确定的值。
- 某些程序设计人员使用不同的方法来表示队列的队头和队尾。
队列的编程实现


5.3 队列的应用
- 打印任务
- 买票排队
- 计算机网络
- 排队论的问题
正如栈一样,队列还有其他丰富的用途。
6 总结
这一部分描述了一些ADT的概念,并且利用三种最常见的抽象数据类型(ADT)阐述了这个概念。
表、栈和队列或许在全部计算机科学中是三个基本的数据结构,大量的例子证明了它们广泛的用途。