数据结构与算法分析读书笔记系列06-优先队列(堆)
Table of Contents
1 模型
优先队列是允许至少下列两种操作的数据结构:Insert(插入),以及DeleteMin(删除最小者),它的工作是找出、返回和删除优先队列中最小的元素。

2 一些简单的实现
有几种明显的方法实现优先队列。我们可以使用一个简单链表在表头O(1)执行插入操作,并遍历该链表以删除最小元,这又需要O(N)时间。另一种方法是,始终让表保持排序状态;这使得插入代价高昂(O(N))而DeleteMin花费低廉(O(1))。基于DeleteMin操作次数从不多于删除操作次数的事实,因此前者可能是更好的想法。
再一种实现优先队列的方法是使用二叉查找树,它对这两种操作的平均运行时间都是O(logN)。使用查找树可能有些过分,因为它支持许许多多并不需要的操作。我们将要使用的基本数据结构不需要指针,它以最坏时间O(N)支持上述两种操作。
3 二叉堆
我们将要使用的这种工具叫做二叉堆(binary heap),它的使用对于优先队列的实现是如此的普遍,以至于当堆(heap)这个词不加修饰的使用时一般都是指该数据结构的这种实现。
3.1 结构性质
堆是一棵被完全填满的二叉树,有可能的例外是在底层,底层的元素从左到右填入。这样的树称为完全二叉树(complete binary tree)。
容易证明,一棵高为h的完全二叉树有2h 到 2h+1 - 1个节点。这意味着,完全二叉树的高是[logN],显然它是O(logN)。一项重要的观察发现,因为完全二叉树很有规律,所以它可以用一个数组表示而不需要指针。
对于数组中任一位置i上的元素,其左儿子在位置2i上,右儿子在左儿子后的单元(2i+1)中,它的父亲则在位置[i/2]上。因此,不仅指针这不需要而且遍历该树所需要的操作也极其简单,在大部分计算机上运行很可能非常快。这种实现方法的惟一问题在于,最大的堆大小需要事先估计,但对于典型的情况这并不成问题。

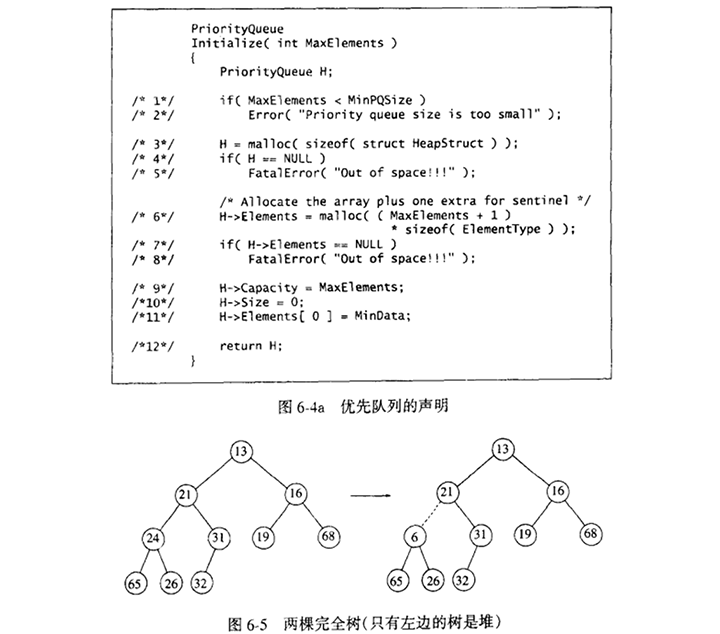
因此,一个堆数据结构将由一个数组(不管关键字是什么类型)、一个代表最大值的整数以及当前的堆大小组成。图6-4显示一个典型的优先队列的申明。

本节我们将始终把堆画成树,这意味着,具体的实现将使用简单的数组。
3.2 堆序性质
使操作被快速执行的性质是堆序(heap order)性。由于我们想要更快速地找出最小元,因此最小元应该在根上。如果我们考虑任意子树也应该是一个堆,那么任意节点就应该小于它的所有后裔。
应用这个逻辑,我们得到堆序性质,在一个堆中,对于每个节点X,X的父亲中的关键字小于(或等于)X中的关键字,根节点除外(它没有父亲)。我们按照惯例假设,关键字是整数,虽然它们可能任意复杂。
根据堆序性质,最小元总可以在根处找到。因此,我们以常数时间完成附加运算FinMin。
3.3 基本的堆操作
Insert插入
为了将一个元素X插入到堆中,我们在下一个空闲位置创建一个空穴,否则该堆将不是完全树。如果X可以放在该穴中而不破坏堆序,那么插入完成。否则,我们把空穴的父节点上的元素移入该空穴中,这样,空穴就朝着根的方向上行了一步。继续该过程直到X能被放入空穴中为止。
这种一般的策略叫做上滤(percolate up);新元素在堆中上滤直到找出正确的位置。

如果要插入的元素是新的最小值,那么它将一直被推向顶端。这样在某一时刻,i将是1,我们就需要令程序跳出while循环。当然我们可以用明确的测试做到这一点,不过我们采用的是把一个很小的值放到位置0处以使while循环得以终止。这个值必须保证小于(或等于)堆中的任何值;我们称之为标记(sentinel)。这种想法类似于链表中头节点的使用。通过添加一条哑信息(dummy piece of information),我们避免了每个循环都要执行一次的测试,从而节省了一些时间。
DeleteMin(删除最小元)
DeleteMin以类似于插入的方式处理。找出最小元是容易的;困难的部分是删除它。当删除一个最小元时,在根节点处产生了一个空穴。由于现在堆少了一个元素,因此堆中最后一个元素X必须移动到该堆的某个地方。如果X可以被放到空穴中,那么DeleteMin完成。不过这一般不太可能,因此我们将空穴的两个儿子中较小者移入空穴,这样就把空穴向下推了一层。重复该步骤直到X可以被放入空穴中。因此,我们的做法是将X置入沿着从根开始包含最小儿子的一条路径上的一个正确的位置。
在堆的实现中经常发生的错误是当堆中存在偶数个元素的时候,此时将遇到一个节点只有一个儿子的情况。我们必须保证假设节点不总是有两个儿子,因此这就涉及到一个附加的测试。

这种算法的最坏情形运行时间为O(logN),平均而言,被放到根处的元素几乎下滤到堆的底层(它所来自的那层),因此平均运行时间为O(logN)。
3.4 其他的堆操作
注意,虽然求最小值操作可以在常数时间完成,但是,按照求最小元设计的堆(也称作最小值堆(min head))在求最大元方面却无任何帮助。
如果我们假设通过某种其他方法得知每一个元素的位置,那么有几种其他的操作开销将变小。下述三种这样的操作均以对数最坏情形运行。
DecreaseKey(降低关键字的值)
DecreaseKey(P, Δ ,H )操作降低位置P处的关键字的值,降值的幅度为正的量 Δ 。由于这可能破坏堆的序,因此必须通过上滤对堆进行调整。该操作堆系统管理程序是有用的:系统管理程序能够使它们的程序以最高的优先级来运行。
IncreaseKey(增加关键字的值)
IncreaseKey(P,Δ,H)操作增加在位置P处的关键字的值,增值的幅度为正的量Δ 。这可以用下滤来完成。许多调度程序自动地降低正在过多的消耗CPU时间的进程的优先级。
Delete(删除)
Delete(P,H)操作删除堆中位置P上的节点。这通过首次执行DecreaseKey(P,∞,H),然后再执行DeleteMin(H)来完成。当一个进程被用户中止(而不是正常终止)时,它必须从优先队列中除去。
BuildHeap(构建堆)
BuildHeap(H)操作把N个关键字作为输入并把它们放入空堆中。显然,这可以使用N个相继的Insert(插入)操作来完成。由于每个Insert将花费O(1)平均时间以及O(logN)的最坏情形时间,因此该算法总的运行时间则是O(N)平均时间而不是O(NlogN)的最坏情形时间。
一般的算法是将N个关键字以任意顺序放入树中,保持结构特性。此时,如果percolateDown(i)从节点i下滤,那么执行图6-14中的该算法创建一棵具有堆序的树(heap-ordered tree)。

定理:包含2b+1-1个节点高为b的理想二叉树(perfect binary tree)的节点的高度的和为2b+1-1-(b+1)。
4 优先队列的应用
4.1 选择问题
输入N个元素以及一个整数k,这N个元素的集可以是全序的。该选择问题是要找出第k个最大的元素。注意,对于任意的k,我们可以求解对称的问题:找出第(N-k+1)个最小的元素,从而k=N/2实际上是一般通过数组排序的算法最困难的情况。这刚好也是最有趣的情形,因为k的这个值称为中位数(median)。
我们给出两个在k=N/2的极端情况下它们均以O(NlogN)运行的算法。这是明显的改进。
算法A
我们将N个元素读入一个数组。然后对该数组应用BuildHeap算法。最后,执行k次DeleteMin操作。从该堆最后提取的元素就是我们的答案。显然,通过改变堆序性质,我们就可以求解原始的问题:找出第k个最大的元素。
算法B
我们使用算法A的思路,在任一时刻我们都将维持k个最大元素的集合S。在前k个元素读入以后,当再读入一个新的元素时,该元素与第k个最大元素进行比较,记这第k个最大的元素为Sk 。注意Sk 是S中的最小元素,它可能是新添加的元素,也可能不是。在输入终了时,我们找到S中最小元素,将其返回,它就是答案。
4.2 事件模拟
例如模拟排队的问题,尤其是要处理的事件涉及下一个到达或下一个离开(哪个发生早就哪个);类似的“最”问题。
5 d-堆
二叉堆是如此简单,以至于它们几乎用在需要优先队列的时候。d-堆是二叉堆的简单推广,它恰像一个二叉堆,只是所有的节点都有d个儿子(因此,二叉堆是2-堆)。
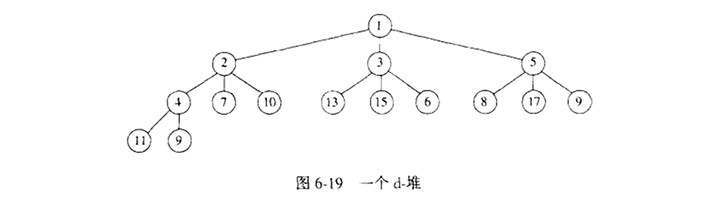
图6-19表示的是一个3-堆。注意,d-堆要比二叉堆浅的多,它将Insert操作的运行时间改进为O(logd N)。然而,对于大的d,DeleteMin操作费时得多,因为树浅了,但是d个儿子中的最小值是必须要找出的。
除不能进行Find外,堆的实现的最明显的缺点是:将两个堆合并成一个堆是困难的操作。这种附加的操作叫做Merge(合并)。存在许多实现堆的方法使得Merge操作的运行时间是O(logN)。下面讨论三种复杂程度不一的数据结构,它们都有效的支持Merge操作。
6 左式堆
设计一种堆结构像二叉堆那样高效地支持合并操作(即以O(N)时间处理一次Merge)而且只使用一个数组似乎很困难。原因在于,合并似乎需要把一个数组拷贝到另一个数组中去,对于相同大小的堆这将花费Θ (N)。正因为如此,所有支持高效合并的高级数据结构都需要使用指针。
像二叉堆那样,左式堆(leftist heap)也具有结构性和有序性。事实上,和所有使用的堆一样,左式堆具有相同的堆序性质;不仅如此,左式堆也是二叉树。左式堆和二叉树间惟一的区别是:左式堆不是理想平衡的,而实际上是趋于非常不平衡。
6.1 左式堆的性质
我们把任一节点X的零路径长(null path length,NPL)Npl(X)定义为从X到一个没有两个儿子的节点的最短路径的长。因此,具有0个或者1个儿子的节点的Npl为0,而Npl(NULL)=-1。
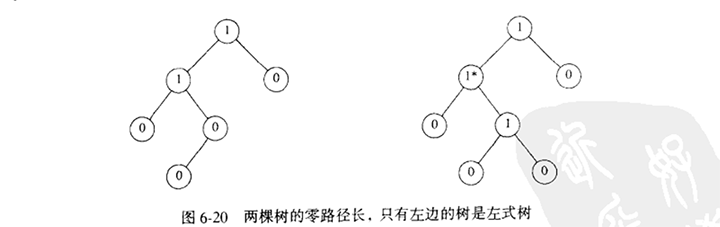
左式堆性质是:对于堆中的每一个节点X,左儿子的零路径长至少与右儿子的零路径长一样大。
因为左式堆趋向于加深左路径,所以右路径应该短。事实上,沿左式堆的右路径确实是该堆中最短的路径。否则,就会存在一条路径通过某个节点X并取得左儿子。此时X则破坏了左式堆的性质。
定理:在右路径上右r个节点的左式树必然至少右2r-1个节点。
从这个定理立刻得到,N个节点的左子树右一条右路径最多含有[log(N+1)]个节点。对左式堆操作的一般思路是将所有的工作放到右路径上进行,它保证树深短。惟一的棘手部分在于,对右路径的Insert和Merge操作可能会破坏左式堆的性质。。事实上,恢复该性质是非常容易的。
6.2 左式堆的操作
对于左式堆的基本操作是合并。注意插入只是合并的特殊情形,因为我们可以把插入看成是单节点堆和一个大的堆的Merge。最小的元素在根处。除数据、左指针和右指针外,每个单元还要有一个指示零路径长的项。
如果这两个堆中有一个堆是空的,那么我们可以返回另外一个堆。否则,为了合并这两个堆,我们需要比较它们的根。首先,我们将具有大的根值的堆与具有小的根值的堆的右子堆合并。这棵树是递归形成的,虽然最后得到的堆满足堆序性质,但是,它不一定为左式堆,不过容易看到树的其他部分必然是左式的,这样一来只要交换根的左儿子和右儿子并更新零路径长,就完成了Merge,新的零路径上是新的右儿子的零路径上加1。


上面提到,我们可以通过把插入项看成单节点堆并执行一次Merge来完成插入。为了执行DeleteMin,只要除掉根而得到两个堆,然后再将这两个堆合并。

7 斜堆
斜堆(skew heap)是左式堆的自调节形式,实现起来极其简单。斜堆和左式堆间的关系类似与伸展树和AVL树间的关系。斜堆是具有堆序的二叉树,但是不存在对树的结构限制。正如同伸展树一样,可以证明任意M次连续操作,总的最坏情形运行时间是O(MlogN)。因此,斜堆每次操作的摊还时间(amortized cost)为O(logN)。
与左式堆相同,斜堆的基本操作也是合并操作。这个Merge例程还是递归的,我们执行与以前完全相同的操作,但有一个例外,即:对于左式堆,我们查看是否左儿子和右儿子满足左式堆堆序性质并交换那些不满足该性质者;但对于斜堆,除了这些右路径上所有节点的最大者不交换它们的左右儿子外,交换是无条件的。
斜堆有一个优点,即不需要附加的空间来保留路径长以及不需要测试确定何时交换儿子。
8 二项队列
虽然左式堆和斜堆每次操作花费O(logN)时间,这有效地支持了合并、插入和DeleteMin,但是还是有改进的余地,因为我们知道,二叉堆以每次操作花费常数平均时间支持插入。二项队列支持所有这三种操作,每次操作的最坏运行时间为O(logN),而插入操作平均花费常数时间。
8.1 二项队列结构
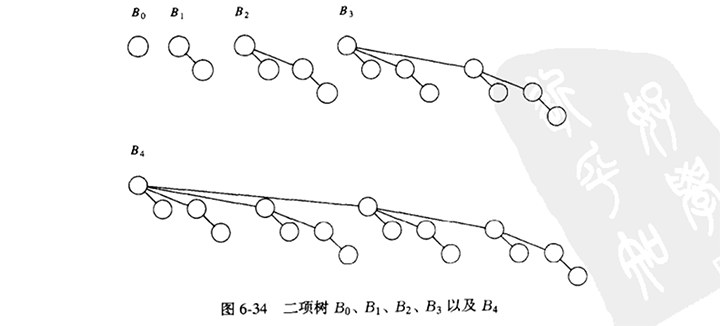
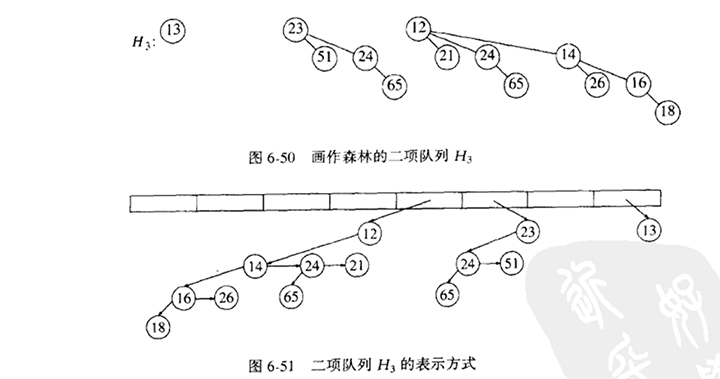
二项队列(binomial queue)不同于我们已经看到的所有优先队列的实现之处在于,一个二项队列不是一棵堆序的树,而是堆序树的集合,称为森林(forest)。堆序树中的每一棵都是有约束的形式,叫做二项树(binomial tree)。每个高度上至多存在一棵二项树。高度为0的二项树是一棵单节点树;高度为k的二项树 Bk 通过将一棵二项树Bk-1附接到另一棵二项树Bk-1的根上而构成。
8.2 二项队列操作
此时,最小元可以通过搜索所有树的根来找出。
合并操作基本上是通过将两个队列加到一起来完成的。为使该操作更高效,我们需要将这些树放到按照高度排序的二项队列中,当然这做起来是一件简单的事情。
插入操作实际上就是特殊情形的合并,我们只要创建一棵单节点树,并执行一次合并。
DeleteMin可以通过首先找到一棵具有最小根的二项树来完成。令该树为Bk ,并令原始的优先队列为H。我们从H的树的森林中除去二项树Bk,形成新的二项树队列H'。再除去Bk 根,得到一些二项树B0, B1, …,Bk-1,它们共同形成优先队列H"。合并H'和H",操作结束。
8.3 二项队列的实现
DeleteMin操作需要快速找出根的所有子树的能力,因此,需要一般树的标准表示方法:每个节点的儿子都存在一个链表中,而且每个节点都有一个指向它的第一个儿子(如果有的话)的指针。该操作还要求:诸儿子按照它们的子树大小排序。二项队列将是二项树的数组。
总之:二项树的每个节点将包含数据、第一个儿子以及右兄弟。二项树中的诸儿子以递减次序排列。



9 总结
在这一节,我们看到优先队列ADT的各种实现方法和用途。标准的二叉堆实现由于简单和速度快从而是精致的。它不需要指针,只需要常数的附加空间,且有效支持优先队列的操作。
考虑了另外的合并操作,发展了三种实现方法,每种都有其独到之处。左式堆是递归强大力量的完美实例。斜堆则是代表缺少平衡原则的一种重要的数据结构。二项队列表明,如何用一个简单的想法来达到好的时间界。
也介绍了优先队列的几个应用,从操作系统的工作调度到模拟。